Nsight Systems VS Nsight Compute VS Pytorch profiler 参考知乎 /Nvidia forum 与MC帮助界面 :
Nsight System(nsys)提供的是系统级别、High-level对应用程序的CPU+GPU交互与负载分析。对于nsys来说,其重点是关注一个CUDA应用程序的CPU执行情况与GPU执行情况,提供诸如内核发射延迟、内存拷贝延迟、GPU同步问题等的分析与统计,用户可以从nsys提供的图表中观测到多线程程序在特定系统 的CPU执行情况以及其各自与GPU交互时GPU内核的执行情况与同步状态。
Nsight Compute(ncu)提供的是内核级别、hardware-level对内核的GPU执行情况的分析。对于ncu来说,其关注的是cuda内核在GPU内的执行瓶颈,例如内存访问模式、内存吞吐量、指令级别的执行效率,使得用户可以发现其内核程序在特定GPU 上的执行情况并改善其内核程序。
Pytorch profiler是在特定框架(Pytroch)下,对Pytorch模型的执行(训练/推理)进行统计与分析,对于使用pytorch框架的用户可以部分代替nsys的用途来定位模型的性能与开销瓶颈,甚至也可以精确到某个kernel的执行情况,但在定位到kernel之后还是推荐使用ncu进行进一步分析。
简单来说,对于CPU/GPU交互、系统层面的宏观应用程序分析,使用nsys,如果是Pytroch代码,可以用Pytorch profiler。定位到内核问题,想看某个算子的在特定GPU上执行情况,用ncu。
在Arch上安装Nsight Systems与Nishgt Compute 首先需要明确,Nsight Systems和Nsight Compute都有cli版本与ui版本,由于我自己使用的Arch不带图形界面,但生产环境在Arch上,因此这里说的在Arch上安装都指的是安装cli。如果有win或mac这类有图形界面的计算机,可以直接去nv官网 下载安装包进行安装。
Arch的好处之一便是Arch有自己的AUR,有直接构建好的Nsight-systems CLI ,目前最新的版本是2025.6.1-1,与官网 给出的最新版本一致。因此直接使用yay安装即可:
按照yay的指令一路yes即可,中途会使用pacman安装多个依赖包。提示安装成功后可以尝试使用nsys指令,可以正常使用便是安装成功了。
1 2 3 4 5 $ nsys
需要注意的是,使用AUR安装的nsys包含了可视化gui界面即nsys-ui,但正常来说nsys-ui的使用需要opengl支持,在Arch上不默认支持opengl,需要进行一些额外的配置来使用gui。类似的,Arch也直接支持一键安装Nsight Compute CLI,ncu甚至是官方源Extra库内的lib,因此直接使用pacman安装即可:
1 sudo pacman -S nsight-compute
安装完成后直接使用ncu指令查看是否安装成功:
1 2 3 4 $ ncu
使用Nsight Compute来Profile内核 简单的写个内核来尝试profile一下,以经典的2维矩阵转置为例,写三个kenrel,分别是naive的直接load全局内存方式、使用shared mem但不缓解bank conflict方式以及使用shared mem且缓解bank conflict。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 __global__ void matrix_transpose_naive (float * input_matrix, float * output_matrix, int H, int W) int row_index = blockIdx.y * blockDim.y + threadIdx.y;int col_index = blockIdx.x * blockDim.x + threadIdx.x;if (row_index >= H || col_index >= W)return ;float tmp = input_matrix[row_index * W + col_index];
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 __global__ void matrix_transpose_smem_with_bc (float * input_matirx, float * output_matrix, int H, int W) float shared_tile[TILE_SIZE][TILE_SIZE];int row_index = blockIdx.y * blockDim.y + threadIdx.y;int col_index = blockIdx.x * blockDim.x + threadIdx.x;int transposed_row_index = blockIdx.x * blockDim.x + threadIdx.y;int transposed_col_index = blockIdx.y * blockDim.y + threadIdx.x;if (row_index >= H || col_index >= W)return ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 __global__ void matrix_transpose_smem (float * input_matirx, float * output_matrix, int H, int W) float shared_tile[TILE_SIZE][TILE_SIZE + 1 ];int row_index = blockIdx.y * blockDim.y + threadIdx.y;int col_index = blockIdx.x * blockDim.x + threadIdx.x;int transposed_row_index = blockIdx.x * blockDim.x + threadIdx.y;int transposed_col_index = blockIdx.y * blockDim.y + threadIdx.x;if (row_index >= H || col_index >= W)return ;
将代码文件命名为matrix_transpose.cu,并附带上主函数,用于发射内核。为了打满内存,可以考虑使用规模较大的数组,这里以10384 x 10384的矩阵为例,主函数代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 int main () float * input_d, *output_d;const int h = 10384 ;const int w = 10384 ;std::vector<float > input_h (h*w, 0 ) ;for (int i = 0 ;i<h;++i)for (int j =0 ;j<w;++j)static_cast <float >(i + 1 );cudaMallocAsync (&input_d, sizeof (float )*h*w, 0 );float >output_h (h*w, 0 ) ;cudaMallocAsync (&output_d, sizeof (float )*h*w, 0 );cudaMemcpyAsync (input_d, input_h.data (), sizeof (float )*h*w, cudaMemcpyHostToDevice);dim3 block_dim (BLOCK_SIZE, BLOCK_SIZE) ;dim3 grid_dim ((w + BLOCK_SIZE - 1 ) / BLOCK_SIZE, (h + BLOCK_SIZE - 1 ) / BLOCK_SIZE) ;cudaMemcpyAsync (output_h.data (), output_d, sizeof (float )*h*w, cudaMemcpyDeviceToHost);cudaDeviceSynchronize ();cudaFreeAsync (input_d, 0 );cudaFreeAsync (output_d, 0 );
此时我们可以调用nvcc进行编译,为不同的内核函数命名不同的可执行文件,以naive内核为例:
1 nvcc -o mt_naive.o ./matirx_transpose.cu
随后可以直接执行编译好的可执行文件,可以考虑在代码内添加一些输出来查看结果是否正确。获得可执行文件之后,便可以开始使用ncu对内核进行profile。使用ncu时一般有两种做法:
使用可视化UI远程连接生产环境对内核进行profile(推荐);
在生产环境的shell内直接profile并将profile得到的rep文件保存,随后传到有可视化UI的环境进行查看(不推荐)。
由于ncu profile出来的结果包含的信息会非常多,一般来说还是推荐使用可视化界面查看rep,当然如果只是宏观的的想看一下内核的执行速度等情况,可以考虑不保存rep,直接在shell内执行ncu。
直接在生产环境使用ncu-cli 确保ncu正确安装的情况下,直接使用对应指令对编译好的可执行文件进行profile:
1 2 3 4 5 6 $ ncu -o profile-default ./mt_naive.o
profile得到的rep文件便可以直接在ncu-ui内打开并查看了。以这种方式得到的rep是按照basic 精细度profile得到的metric。为了更方便的查看内核的执行情况,推荐直接使用full 参数获得。具体的metric/精细度区别可以使用ncu -llist-sets查看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ ncu --list-sets
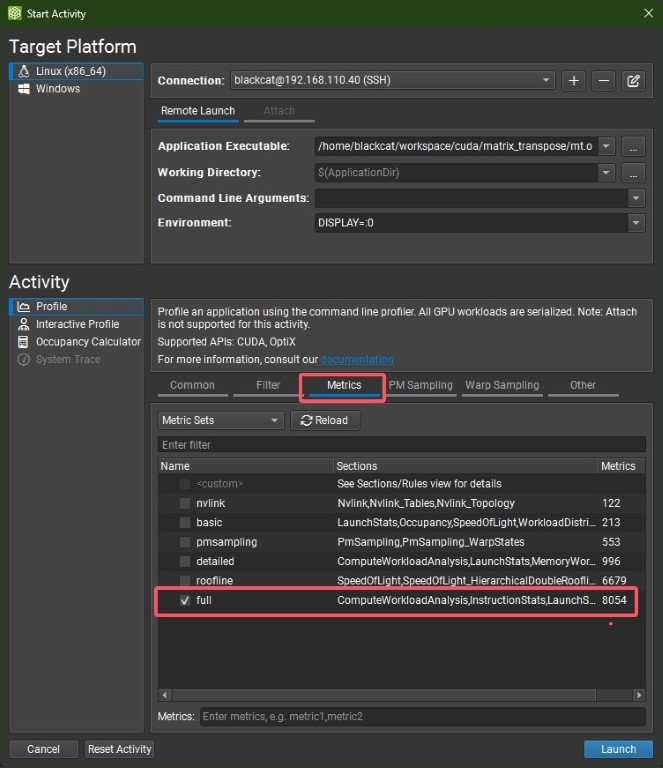
在ncu指令后添加--set full参数便可以获得full 精细度的metric,即:
1 ncu --set full -o profile-full ./mt_naive.o
ncu-cli还拥有很多进阶功能可以使用,但大部分时候对某个内核进行profile时直接使用full metric已经足够。例如多进程、抽样等功能可以参考ncu-cli的官方手册
在ncu-ui内连接远程环境 如果直接使用ncu-ui,相比使用cli版本会更方便,我们也可以直接通过ssh远程连接生产环境(只要环境内装有ncu即可)并进行profile,随后直接获得rep文件并查看。打开ncu-ui后在左上角的Connection菜单中选择Start Activity,打开界面便可以配置SSH连接,并选择可执行文件,随后对本机保存的rep文件进行命名,便可以开始profile。同样的,为了获得full 精细度的metric,我们在下面的metric菜单内选择full 选项。
NCU报错权限不足 如果在使用ncu-cli或ssh连接远端并profile时,报以下错误:
1 2 ==ERROR== ERR_NVGPUCTRPERM - The user does not have permission to access NVIDIA GPU Performance Counters on the target device 0.
参考NV给出的链接 与知乎文章 ,在*418.43+*驱动版本之后,Linux环境下的NV旗下GPU会对GPU性能计数器的访问进行鉴权,必须有管理员权限才可以完全获取GPU的性能计数器。
对于cli用户,解决方案很简单,直接使用sudo即可。但也可以一劳永逸的配置性能计数器的权限降为普通用户可使用,对于Linux环境,可以执行以下指令:
1 2 3 4 5 6 7 # 创建配置文件,允许所有用户访问 # 重启系统使配置生效
对于win用户,也可以直接右键并以管理员身份运行 或在NV的控制面板进行配置,具体可以参考上面的知乎链接。但需要注意是远端连接的生产机器还是本机没有权限,一般都是对远端生产环境的权限进行配置即可。
在ncu-ui内查看内核执行情况 在得到rep后,打开查看我们可以发现,即使在basic 精细度模式下,rep内包含的信息也非常多,对于初学者可能不知道要关注哪些部分。其实如果对于一些简单的内核,如果内核的发射规模足够大,我们的优化目标是尽可能最大化计算吞吐量(Compite Throughput)和 内存吞吐量(Memory Throughput) 。前者决定了我们每个线程内整体的数据处理 能力,后者代表了我们从存储单元内读取或写入 数据的能力。由于一般的cuda内核都会使用全局内存,全局内存的读写又非常耗时,一定会stall线程的执行,我们的目标是尽量减少stall,尽量使用联合访问、共享内存等这类方式减少stall耗时以提高计算在线程执行内的占比,并提高内存吞吐量,最终达到削减线程执行时钟周期的最终目的。
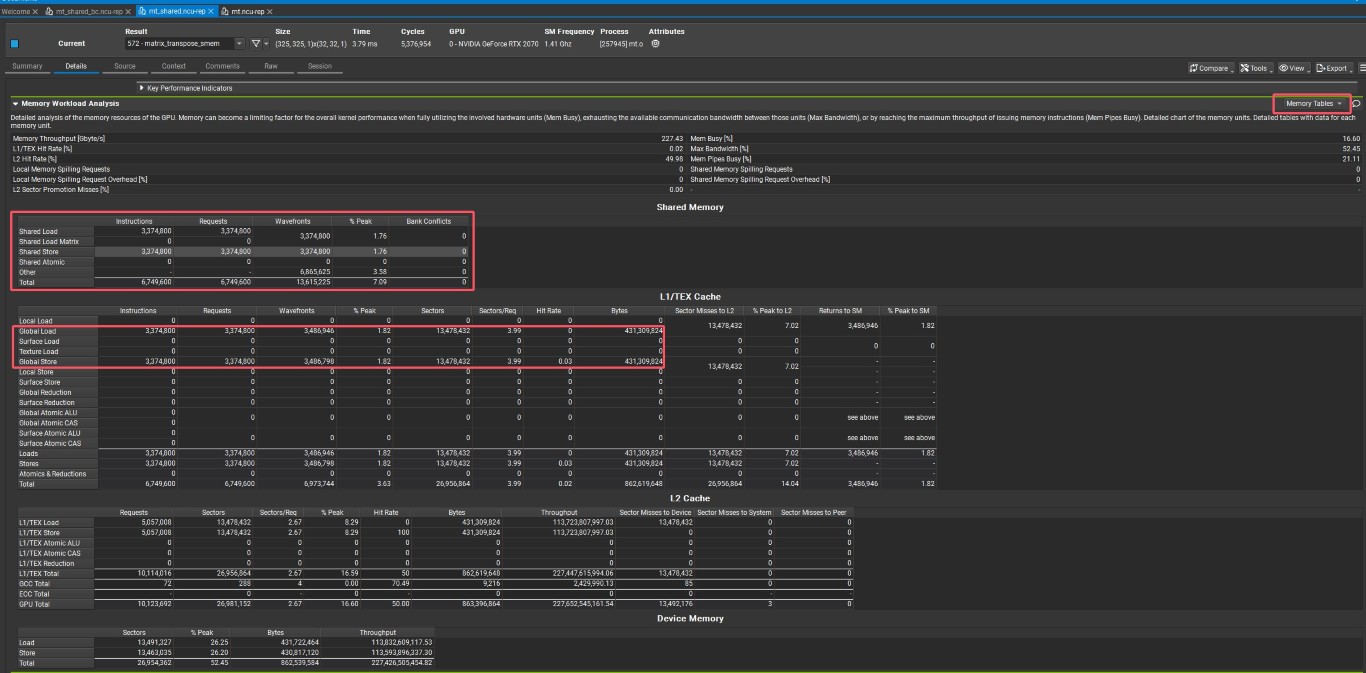
ncu给到的rep在full 模式下,总览(Summary)单元有时候会直接给出有效的信息,例如我们在使用naive方式的转置内核,Summary直接指出我们的全局内存访问是非联合的。
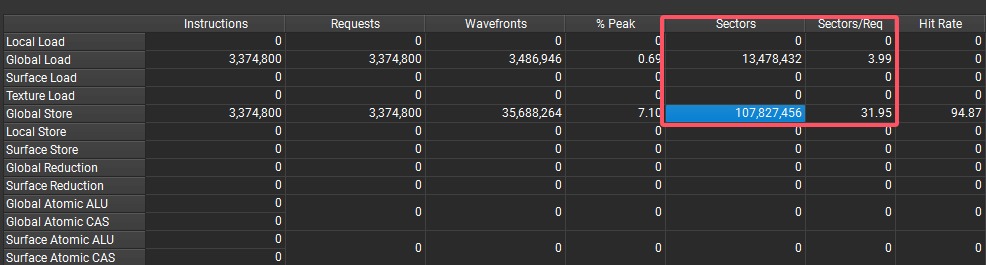
由于给的示例内核是矩阵转置,该内核基本上不存在计算耗时,因此我们的主要任务是提高内存吞吐量。因此我们可以观察Details单元内的Memory workload analysis,full 模式下,ncu会给出Memory Table ,选择展示内存表单可以很直观的查看诸如共享内存访问、全局内存访问的详细情况。由于之前给出的例子刚好是三种内核,分别对应全局内存非联合访问 、共享内存Bank Conflict 与共享内存无Bank Conflict 。我们可以看到内存表单内关于全局内存和共享内存的内容,可以发现当我们没有正确联合访问共享内存时,其Sectors(可以理解为访问事务的数量)会比正常联合访问的事务要多得多,说明SM在执行时很难将warp内的线程request的内存地址进行联合,导致了访问全局内存更为耗时。同理,我们也能看到共享内存相关表格内是否有Bank Conflict,在对TILE的大小进行修改后,Bank Conflict几乎全部消失了。
具体其他metric的观察方式可以参阅ncu官方手册 。