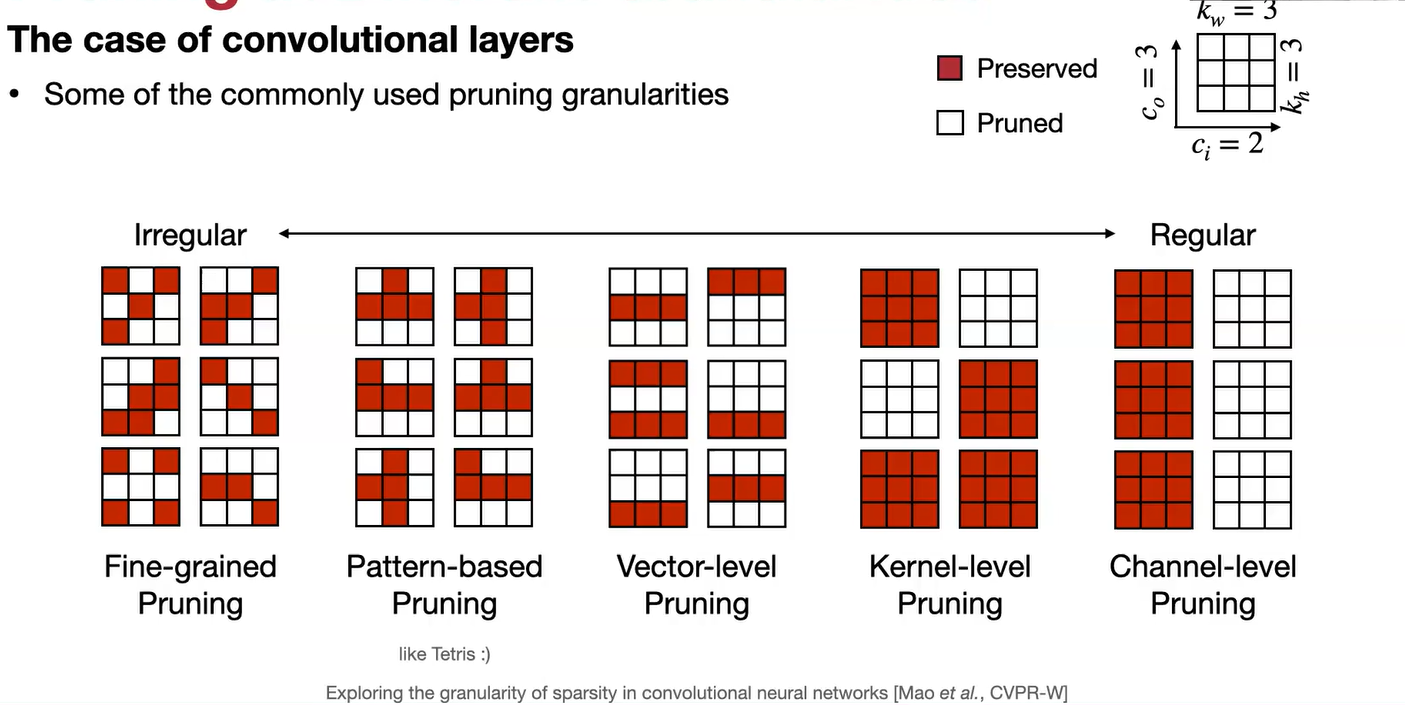
import copy import torchvision from apex.contrib.sparsity import ASP
# Load dense model resnet50_dense = torchvision.models.resnet50(weights="ResNet50_Weights.IMAGENET1K_V1")
# Initialize sparsity mode before starting sparse training resnet50_sparse = copy.deepcopy(resnet50_dense) ASP.prune_trained_model(resnet50_sparse, optimizer)
# Re-train model for e inrange(0, epoch): for i, (image, target) inenumerate(data_loader): image, target = image.to(device), target.to(device) output = resnet50_sparse(image) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step()
# Save model torch.save(resnet50_sparse.state_dict(), "sparse_finetuned.pth")
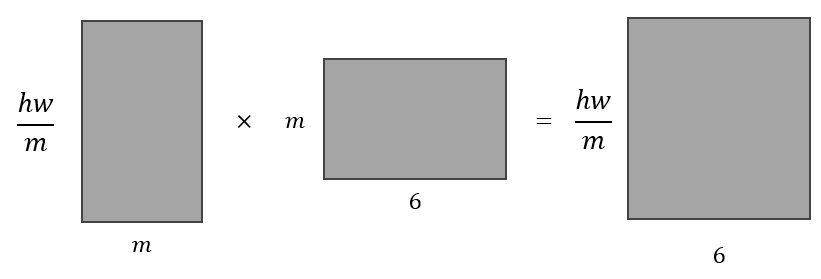
""" reshape matrix into m-dimensional vectors: (h,w) -> (hw/m, m) """ defreshape_1d(matrix, m): # If not a nice multiple of m, fill with zeroes. if matrix.shape[1] % m > 0: mat = torch.cuda.FloatTensor(matrix.shape[0], matrix.shape[1] + (m-matrix.shape[1]%m)).fill_(0) mat[:, :matrix.shape[1]] = matrix shape = mat.shape return mat.view(-1,m),shape else: return matrix.view(-1,m), matrix.shape
""" return all possible m:n patterns in a 1d vector """ valid_m4n2_1d_patterns = None defcompute_valid_1d_patterns(m,n): # Early exit if patterns was already created. global valid_m4n2_1d_patterns
if m==4and n==2and valid_m4n2_1d_patterns isnotNone: return valid_m4n2_1d_patterns patterns = torch.zeros(m) patterns[:n] = 1 valid_patterns = torch.tensor(list(set(permutations(patterns.tolist())))) if m == 4and n == 2: valid_m4n2_1d_patterns = valid_patterns return valid_patterns
""" m:n 1d structured best """ defmn_1d_best(matrix, m, n): # Find all possible patterns. patterns = compute_valid_1d_patterns(m,n).cuda()
# Find the best m:n pattern (sum of non-masked weights). mask = torch.cuda.IntTensor(matrix.shape).fill_(1).view(-1,m) mat,shape = reshape_1d(matrix,m) pmax = torch.argmax(torch.matmul(mat.abs(),patterns.t()), dim=1) mask[:] = patterns[pmax[:]] mask = mask.view(matrix.shape) return mask
import torch from torch import autograd, nn import torch.nn.functional as F from pytorch_quantization.nn import QuantConv2d from torch.nn.modules.utils import _pair
classSparse_NHWC(autograd.Function): """" Prune the unimprotant edges for the forwards phase but pass the gradient to dense weight using SR-STE in the backwards phase"""
@staticmethod defforward(ctx, weight, N, M, decay = 0.0002):
ctx.save_for_backward(weight) output = weight.clone() length = weight.numel() group = int(length/M)
weight_temp = weight.detach().abs().permute(0,2,3,1).reshape(group, M) index = torch.argsort(weight_temp, dim=1)[:, :int(M-N)]